Clean Architecture
An approach to implement Clean Architecture and its benefits

Overview
The purpose of Clean architecture is the separation of our core logic from the inputs and outputs of the system in which it lives. We should always attempt to have a business logic layer that has zero dependencies on how we receive requests, be it RESTful APIs, Queues, jobs, or an event bus. Nor should it care how we interact with our data - a database, a CSV file, a 3rd party API etc.
The clean architecture pattern gives us the ability to isolate our core logic from all other concerns. Leveraging this, we can more easily switch out different data sources and provide additional methods of ingestion whilst avoiding significant impact or large refactoring of the core logic.
In one of my previous roles, we worked with AWS technologies and implemented a serverless platform architecture. A core component of this was the use of Lambda functions. We made heavy use of clean architecture to allow us to flexibly handle various input types. This involved taking the incoming stream, identifying the source of the stream and routing messages towards the correct adapter. The flexibility this gave us is that we could have a single handler per message, available through multiple adapters. Essentially our core logic did not care how it was invoked, It was independent of this, allowing us to add additional adapters without affecting the core logic.
This is just one example of the benefits of using clean architecture. Let's set out how to create a solution using clean architecture by taking a closer look at the structure.
Structure
Clean architecture focuses on the separation of certain layers within our solution.
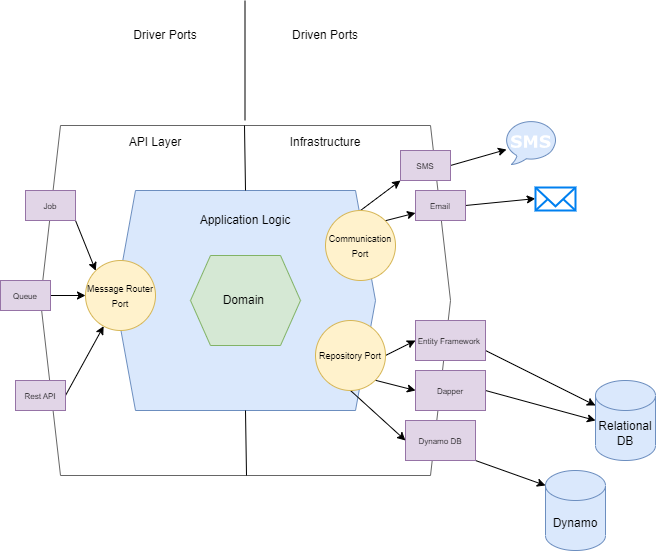
The flow from left to right above uses the following logic. The core is represented here by the application and domain sections where our business and enterprise logic resides. The API layer represents the inputs available to the consumers of the service, be that via REST or a scheduled job etc. The infrastructure layer contains the logic to interact with any data or 3rd party dependencies.
The key takeaway from the flow above should be that no dependencies are flowing out from the core of our system. We only allow the outer sections of our architecture to be able to refer to the core of the system.
Visually this would look like the following.
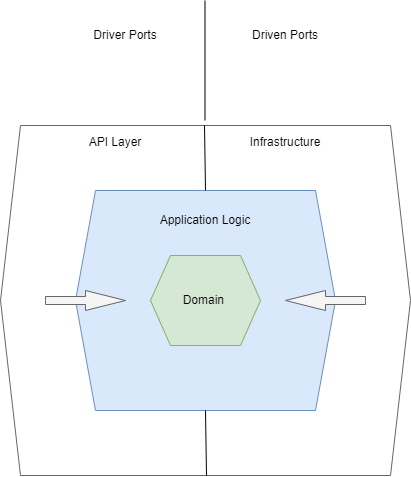
And representing this within our solution would look something like this.
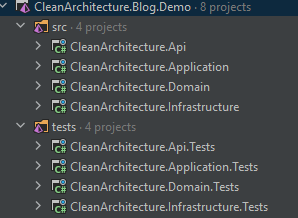
If we dig into these layers it should help to form a clearer picture.
API layer
This layer holds the presentation layer of our solution. This includes the following components:
Controllers
The Client App
Request and response models
Service registration
The application layer only has a direct dependency on the Application and Domain layers only as it looks inwards to the core of our structure.
Note: You would most likely have a dependency on the infrastructure here to facilitate dependency injection but this would be an exception to the rule
Application Layer
This layer represents the core business rules of our solution. Its only dependency should be on the domain layer.
The application layer should be used to hold the interfaces required by the other layers of our solution to fulfil the required functionality. For example, if the API layer needs to request a service that provides e-mail functionality, it would reference the interface IEmailService from the application layer, with the implementation of this interface living within the Infrastructure layer.
Another feature of the Application layer should be the use of CQRS (Command Query Responsibility Segregation). This allows us to create a single handler for each message type we are attempting to handle. This touches back on my earlier example of the message routing used by the Lambdas in one of my previous projects. A common tool often used to facilitate this would be something like Mediatr. This can be overkill at times and a simple implementation using the Liskov Substitution principle from SOLID design principles should tackle most scenarios, without the same overhead.
Domain Layer
The Domain layer should include components such as the following:
Enums
Types
Exceptions
Entities
Interfaces
Infrastructure Layer
The Infrastructure layer provides all the functionality required for the solution to access external resources. This could include the following for example:
Database Repositories
3rd party APIs
SMS
SMTP (e-mail)
File Systems
Benefits
Testing becomes easier as we can isolate the layers of our system more easily.
The solution becomes easier to maintain as we have separated the concerns between the various layers.
Extending the functionality of the solution to handle different adapters becomes easier due to loose coupling. Want to integrate with Azure? No problem, just create an adapter to handle the incoming message type and hook it into the existing business logic.
Note: As with anything, good things can be taken too far. Avoid creating something too complex that it becomes a pain to work with. Be careful not to over-engineer your solution. If you feel some scenarios need to bend the rules in the name of being pragmatic, then so be it.



