AWS Glue - Defining resources in CloudFormation for use with Athena

Introduction
Recently I have been working on a project that required a means of performing ETL operations on an S3 source bucket for the purpose of analysis. I decided to explore using a 'Crawler' provided as a service by AWS Glue in order to facilitate this. There are some gaps in the currently available documentation, so hopefully this will prove useful as a reference, not only for myself, but others that would like to provide these resources using Infrastructure as Code (IaaC).
Technology choices
- CloudFormation
- Athena
- Glue
Note : This should follow a similar pattern in Terraform and so should still be informative for those using Terraform in place of CloudFormation
Let's create Glue resources needed for Athena
So we want to be able to query some S3 objects using Athena. To facilitate this, we need the following resources in Glue:
- Glue Database
- Glue Table
The Glue table can be created either manually or using a Crawler. We will use a Crawler in this example for the following reasons:
- Easier to manage for long term applications
- Handles schema changes based on the S3 object data automatically
- Useful configuration options
Note: Manually creating tables has it's place. Either to facilitate one off requests or out of process querying. It may also be the case that if you know your schema upfront, you may be consuming data from a source out of your control and so need to define columns as JSON encoded strings to give you better flexibility with queries.
Resource Definitions
The following shows a basic example of the required resources.
Glue database:
GlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Description: "Description of Database"
Name: "my-database"
Nothing complicated to note here. Just set your AWS account id as the CatlogId and give it a name.
see: CloudFormation - Glue Database
Glue Security Configuration:
GlueSecurityConfiguration:
Type: AWS::Glue::SecurityConfiguration
Properties:
EncryptionConfiguration:
CloudWatchEncryption:
CloudWatchEncryptionMode: 'SSE-KMS'
KmsKeyArn: <ARN of KMS key>
JobBookmarksEncryption:
JobBookmarksEncryptionMode: 'DISABLED'
S3Encryptions:
- S3EncryptionMode: 'DISABLED'
Name: "My Security Configuration"
The example above provides encryption of any CloudWatch logs generated by your Crawler with the S3 and Job Bookmark encryption set as 'DISABLED'.
S3 encryption allows you to add 'at rest' encryption to any data written to S3 by your Crawler:
S3Encryptions:
- S3EncryptionMode: 'SSE-KMS'
KmsKeyArn: <ARN of KMS key>
The options for 'S3EncryptionMode' are 'DISABLED', 'SSE-KMS' and 'SSE-S3'.
Job bookmark encryption can only be provided with 'CSE-KMS' encryption or be set as 'DISABLED'.
JobBookmarksEncryption:
JobBookmarksEncryptionMode: 'CSE-KMS'
KmsKeyArn: <ARN of KMS key>
Job Bookmarks are used by Glue to track what data has already processed between running the ETL jobs.
see: CloudFormation - Glue Security Configuration Working with Security Configurations Job Bookmarks.
Note: 'KmsKeyArn is only required when setting the encryption mode as 'SSE-KMS'.
Glue Crawler:
GlueCrawler:
Type: AWS::Glue::Crawler
Properties:
Configuration: "{\"Version\": 1.0,\"Grouping\":{\"TableGroupingPolicy\":\"CombineCompatibleSchemas\"},\"CrawlerOutput\":{\"Partitions\":{\"AddOrUpdateBehavior\":\"InheritFromTable\"}}}"
CrawlerSecurityConfiguration: !Ref GlueSecurityConfiguration
DatabaseName: !Ref GlueDatabase
Description: "Crawler for objects stored in my S3 bucket"
Name: "MyCrawler"
RecrawlPolicy:
RecrawlBehavior: "CRAWL_EVERYTHING"
Role: !Ref GlueCrawlerRole
Schedule:
ScheduleExpression: cron(0 3 * * ? *)
SchemaChangePolicy:
DeleteBehavior: "DEPRECATE_IN_DATABASE"
UpdateBehavior: "UPDATE_IN_DATABASE"
TablePrefix: "my_database_"
Targets:
S3Targets:
- Path: !Sub "s3://${Stack Name}-${Environment}-<bucket name>/"
Exclusions:
- "**/excluded-folder/**"
This one is slightly more involved, so lets go through those which aren't obvious at first glance.
Configuration:
We can use the configuration to change the behaviour of the Crawler in regards to how it attempts to handle changes in the data store that affects the schema or partitions generated between runs.
We can provide JSON to set a number of options when declaring our resource in CloudFormation.
In the above example, we are setting the following options:
- Inherit from table
- Combine compatible schemas
When we set 'AddOrUpdateBehavior' to 'InheritFromTable' all partitions will inherit any metadata associated with the table. Such as:
- Classification
- Input format
- Output format
- SerDe information
- Schema
If any of these values change at the table level, they will be reflected on to the partitions.
Setting the 'TableGroupingPolicy' to be 'CombineCompatibleSchemas' makes sure that if we have a schema that has been altered at some point; such as adding a new field or removing a field, then these changes don't result in the generation of a new table. Instead, the differing schemas are merged resulting in a table combining the properties of each schema.
See the following link which includes example configuration options: Crawler Configuration
ReCrawl Policy
This setting controls whether the crawler will re-scan the entire dataset on every run, only those new folders/objects that have been added since the previous run or only changes as identified by S3 events. The following options are allowed:
- CRAWL_EVERYTHING
- CRAWL_NEW_FOLDERS_ONLY
- CRAWL_EVENT_MODE
SchemaChangePolicy
The following options control what actions take place depending on changes to the source data:
Delete Behaviour
The following options are available for delete behaviour:
- Log
- If a table or a partition already exists, only log that a change was detected
- Delete From Database
- Delete any tables or partitions no longer detected
- Deprecate In Database
- Add a property to table named 'DEPRECATED' and mark this with a timestamp
Update Behaviour
The following options are available for update behaviour:
- Log
- If a table or a partition is no longer detected, only log that it was no longer found. Do not delete it.
- Update in Database
- Update the table based on changes detected to the table or partition
For information around this and the other options see: Glue Crawler - CloudFormation
Table Prefix
A small thing here. Be careful not to include '-' within the table name prefix. This caused issues for me when trying to perform partition fixes. I didn't dig into this too much, but if you encounter something similar this may be something to watch out for.
We understand the main resources, but what else do we need?
Besides the main Glue resources already mentioned there a number of supporting resources.
Creating the Crawler Role and Policies
The following shows the permissions assigned against the role for our Crawler:
CrawlerRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service:
- "glue.amazonaws.com"
Action:
- "sts:AssumeRole"
ManagedPolicyArns:
- "arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole"
CrawlerPolicy:
Type: AWS::IAM::Policy
Properties:
Roles:
- !Ref CrawlerRole
PolicyName: glue_crawler_bucket_access
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Sid: "AllowS3Access"
Action:
- "s3:GetObject"
- "s3:ListBucket"
Resource:
- !Sub "arn:aws:s3:::${stack name}-${Environment}-<bucket name>/*"
- Effect: Allow
Sid: "GlueEncryptionKeyPermissions"
Action:
- "kms:Encrypt"
Resource:
- !GetAtt SecurityConfigurationEncryptionKey.Arn
- Effect: Allow
Sid: "LogPermissions"
Action:
- "logs:AssociateKmsKey"
Resource:
- "*"
Here, we have taken advantage of the managed policy 'AWSGlueServiceRole' to do a lot of the heavy lifting. You can view the permissions granted for this policy here: AWSGlueServiceRole
Besides these, we specifically add permissions for the following resource actions:
- Read permissions on our S3 source bucket
- Permission to encrypt using an encryption key when writing to the Crawler log group
- Permission to associate our KMS key with the target log group
Creating the KMS Key
An example of the KMS key definition is as follows:
SecurityConfigurationEncryptionKey:
Type: AWS::KMS::Key
Properties:
Description: "Symmetric key used to encrypt AWS Glue CloudWatch logs at rest"
EnableKeyRotation: true
KeySpec: SYMMETRIC_DEFAULT
KeyPolicy:
Version: "2012-10-17"
Statement:
- Sid: "EnableRootAccess"
Effect: Allow
Principal:
AWS: !Sub "arn:aws:iam::${AWS::AccountId}:root"
Action:
- "kms:*"
Resource:
- "*"
- Sid: "AllowLogsKMSAccess"
Effect: Allow
Principal:
Service: "logs.${AWS::Region}.amazonaws.com"
Action:
- "kms:Decrypt*"
- "kms:Encrypt*"
- "kms:ReEncrypt*"
- "kms:GenerateDataKey*"
- "kms:Describe*"
Resource:
- "*"
Condition:
ForAnyValue:ArnEquals:
"kms:EncryptionContext:aws:logs:arn": !Sub "arn:aws:logs:${AWS::Region}:${AWS::AccountId}:*"
- Sid: "AllowCrawlerKMSAccess"
Effect: Allow
Principal:
AWS: !GetAtt CrawlerRole.Arn
Action:
- "kms:Decrypt*"
- "kms:Encrypt*"
- "kms:ReEncrypt*"
- "kms:GenerateDataKey*"
- "kms:Describe*"
Resource:
- "*"
Condition:
ForAnyValue:ArnEquals:
"kms:EncryptionContext:aws:logs:arn": !Sub "arn:aws:logs:${AWS::Region}:${AWS::AccountId}:*"
See the following regarding Glue and encryption: Glue - Data Protection
What does that look like altogether?
We now have all the required resources to get us up and running. The full template should look something like the following:
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: "A template to create all the Analysis infrastructure."
Parameters:
Environment:
Description: "The environment type"
Type: "String"
AllowedValues:
- "dev"
- "build"
- "staging"
- "integration"
- "production"
ConstraintDescription: must be dev, build, staging, integration or production
Resources:
GlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Description: "Description of Database"
Name: "my-database"
GlueCrawler:
Type: AWS::Glue::Crawler
Properties:
Configuration: "{\"Version\": 1.0,\"Grouping\":{\"TableGroupingPolicy\":\"CombineCompatibleSchemas\"},\"CrawlerOutput\":{\"Partitions\":{\"AddOrUpdateBehavior\":\"InheritFromTable\"}}}"
CrawlerSecurityConfiguration: !Ref GlueSecurityConfiguration
DatabaseName: !Ref GlueDatabase
Description: "Crawler for objects stored in my S3 bucket"
Name: "MyCrawler"
RecrawlPolicy:
RecrawlBehavior: "CRAWL_EVERYTHING"
Role: !Ref GlueCrawlerRole
Schedule:
ScheduleExpression: cron(0 3 * * ? *)
SchemaChangePolicy:
DeleteBehavior: "DEPRECATE_IN_DATABASE"
UpdateBehavior: "UPDATE_IN_DATABASE"
TablePrefix: "my_database_"
Targets:
S3Targets:
- Path: !Sub "s3://${Stack Name}-${Environment}-<bucket name>/"
Exclusions:
- "**/excluded-folder/**"
GlueSecurityConfiguration:
Type: AWS::Glue::SecurityConfiguration
Properties:
EncryptionConfiguration:
CloudWatchEncryption:
CloudWatchEncryptionMode: 'SSE-KMS'
KmsKeyArn: <ARN of KMS key>
JobBookmarksEncryption:
JobBookmarksEncryptionMode: 'DISABLED'
S3Encryptions:
- S3EncryptionMode: 'DISABLED'
Name: "My Security Configuration"
CrawlerRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service:
- "glue.amazonaws.com"
Action:
- "sts:AssumeRole"
ManagedPolicyArns:
- "arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole"
CrawlerPolicy:
Type: AWS::IAM::Policy
Properties:
Roles:
- !Ref CrawlerRole
PolicyName: glue_crawler_bucket_access
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Sid: "AllowS3Access"
Action:
- "s3:GetObject"
- "s3:ListBucket"
Resource:
- !Sub "arn:aws:s3:::${stack name}-${Environment}-<bucket name>/*"
- Effect: Allow
Sid: "GlueEncryptionKeyPermissions"
Action:
- "kms:Encrypt"
Resource:
- !GetAtt SecurityConfigurationEncryptionKey.Arn
- Effect: Allow
Sid: "LogPermissions"
Action:
- "logs:AssociateKmsKey"
Resource:
- "*"
SecurityConfigurationEncryptionKey:
Type: AWS::KMS::Key
Properties:
Description: "Symmetric key used to encrypt AWS Glue CloudWatch logs at rest"
EnableKeyRotation: true
KeySpec: SYMMETRIC_DEFAULT
KeyPolicy:
Version: "2012-10-17"
Statement:
- Sid: "EnableRootAccess"
Effect: Allow
Principal:
AWS: !Sub "arn:aws:iam::${AWS::AccountId}:root"
Action:
- "kms:*"
Resource:
- "*"
- Sid: "AllowLogsKMSAccess"
Effect: Allow
Principal:
Service: "logs.${AWS::Region}.amazonaws.com"
Action:
- "kms:Decrypt*"
- "kms:Encrypt*"
- "kms:ReEncrypt*"
- "kms:GenerateDataKey*"
- "kms:Describe*"
Resource:
- "*"
Condition:
ForAnyValue:ArnEquals:
"kms:EncryptionContext:aws:logs:arn": !Sub "arn:aws:logs:${AWS::Region}:${AWS::AccountId}:*"
- Sid: "AllowCrawlerKMSAccess"
Effect: Allow
Principal:
AWS: !GetAtt CrawlerRole.Arn
Action:
- "kms:Decrypt*"
- "kms:Encrypt*"
- "kms:ReEncrypt*"
- "kms:GenerateDataKey*"
- "kms:Describe*"
Resource:
- "*"
Condition:
ForAnyValue:ArnEquals:
"kms:EncryptionContext:aws:logs:arn": !Sub "arn:aws:logs:${AWS::Region}:${AWS::AccountId}:*"
Create the stack in CloudFormation and we can start to look at providing some data for Athena to work with.
What do we see in Athena
Let's provide some example data to store in our bucket:
{"CHANGE":0.68,"PRICE":99.68,"TICKER_SYMBOL":"NFLX","SECTOR":"TECHNOLOGY"}
{"CHANGE":-1.73,"PRICE":47.02,"TICKER_SYMBOL":"QXZ","SECTOR":"RETAIL"}
{"CHANGE":-7.73,"PRICE":88.12,"TICKER_SYMBOL":"ALY","SECTOR":"ENERGY"}
{"CHANGE":0.83,"PRICE":28.89,"TICKER_SYMBOL":"CRM","SECTOR":"HEALTHCARE"}
{"CHANGE":-1.3,"PRICE":99.65,"TICKER_SYMBOL":"NFS","SECTOR":"ENERGY"}
{"CHANGE":-12.2,"PRICE":726.99,"TICKER_SYMBOL":"AMZN","SECTOR":"TECHNOLOGY"}
{"CHANGE":3.2,"PRICE":89.71,"TICKER_SYMBOL":"QXZ","SECTOR":"HEALTHCARE"}
{"CHANGE":-0.08,"PRICE":4.74,"TICKER_SYMBOL":"HJK","SECTOR":"TECHNOLOGY"}
{"CHANGE":0.38,"PRICE":45.94,"TICKER_SYMBOL":"WFC","SECTOR":"FINANCIAL"}
{"CHANGE":-2.23,"PRICE":114.8,"TICKER_SYMBOL":"IOP","SECTOR":"TECHNOLOGY"}
{"CHANGE":0.74,"PRICE":51.09,"TICKER_SYMBOL":"RFV","SECTOR":"FINANCIAL"}
{"CHANGE":8.89,"PRICE":199.89,"TICKER_SYMBOL":"TBV","SECTOR":"HEALTHCARE"}
Save the above as a .txt file and upload it into your bucket. I have uploaded into a specified path in order to take advantage of partitioning:
2022/07/22/10
This will create a partition on the year, month, day and hour which will greatly improve querying when generating large volumes of data. For example, we were working with FireHose to funnel large amounts of data into S3 before being consumed by Athena. If we didn't take advantage of partitioning queries would be extremely slow running. If you do work with a service like FireHose this will all be taken care of by default. But I felt it worth showing here as it is important when using Athena in a production environment.
You can look into this in more detail here:
Now let's navigate in the console to AWS Glue > Crawlers:
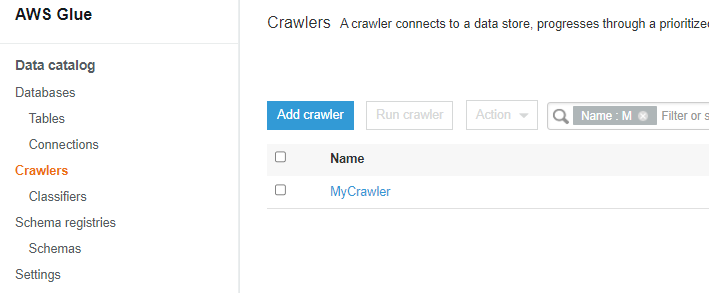
We can see the Crawler we created is now waiting to be run. Select the Crawler and click the 'Run Crawler' button. If the permissions are set up correctly, you should see this complete and the 'Tables Added' column show as 1.
If we go now to the Athena service we should see the option to select our table:
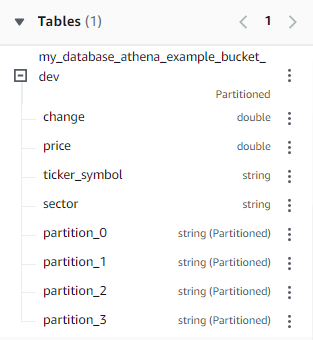
Let's just select everything from our table (there are only a few rows).
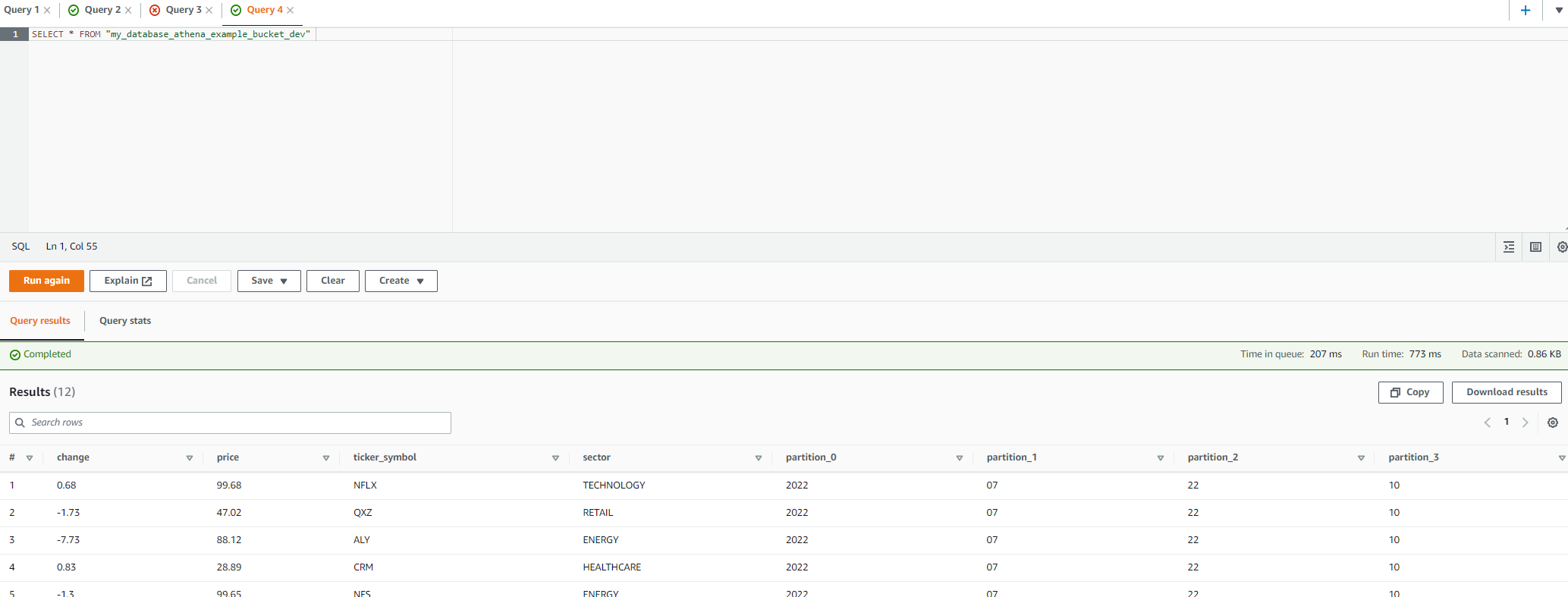
We can see here that the crawler has correctly determined the columns and included the partitions which were inferred from the file path in the bucket. When running on a schedule, any changes to the source data will be handled and reflected automatically, we don't have to do anything else!
Conclusion
Hopefully the above will help people who are thinking of working with Glue or Athena and make use of CloudFormation, while also filling the gaps not covered in the current official documentation. The power of Glue to consume source data from S3 and perform ETL operations for us to consume via Athena is fantastic, so if you have the opportunity, make use of it.
Thanks for reading.



