Athena- Getting Started

What is AWS Athena?
Athena is a serverless 'interactive query service' that can be used to perform SQL queries against a number of sources within AWS.
Being serverless, it has low management requirements as well as low cost.
What Problem is it trying to solve?
Athena gives us the ability to analyse data that we store in various AWS services such as CloudTrail, Redshift and S3. This can be surfaced in many different ways, such as integrating with Amazon QuickSight, Elastic or any other business intelligence tooling.
Perhaps you are streaming data from a number of different sources using Kinesis FireHose for example. We then want to be able to query that RAW data and surface it in some way for further analysis. With Athena we can do this without having to move or make transformations to the data.
How can we use it?
There are a number of ways we can interact with Athena:
Console
The first option is using Athena directly within the AWS console.
You can use the query editor browser window to set your data source, create tables, run and save queries, etc.
Example:
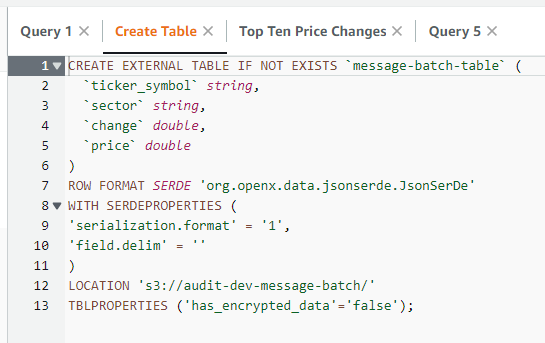
The following shows a an example of creating a new table.
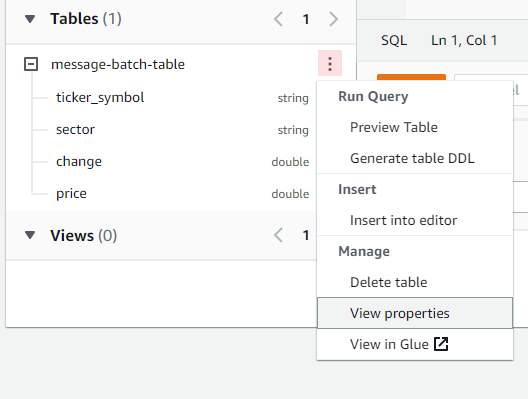
We can use the table drop-down to see the table columns with some useful options for running queries against the table and viewing the underlying definition in Glue (we will touch on this later).
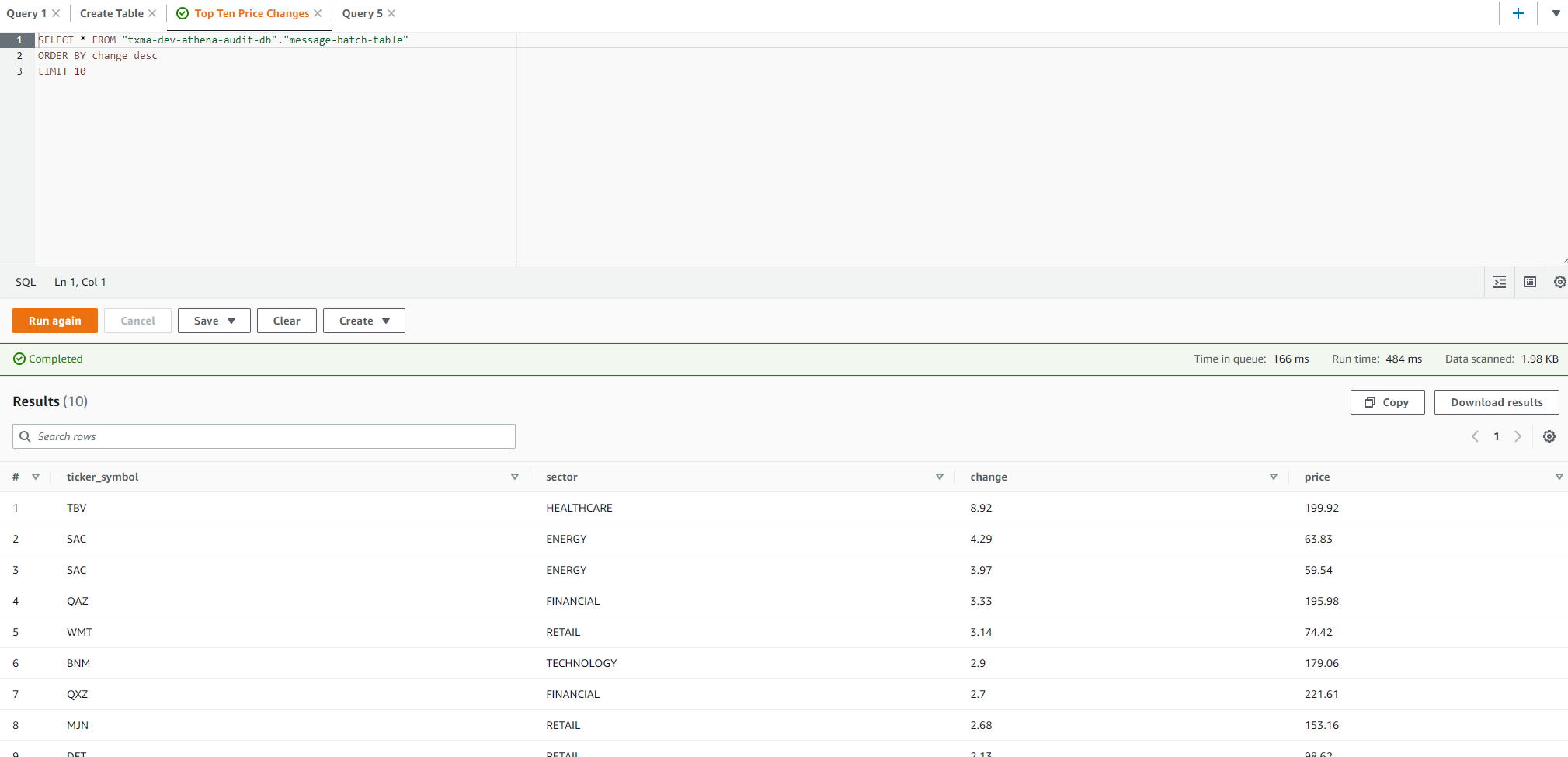
Running queries shows the output in the 'Results' section below the query box with the option to copy or download the results.
There are other useful features in the console that can be explored and are easiest done by getting your fingers dirty and playing around with some test data; Such as the 'Keyboard Shortcuts' button on the lower right hand side of the query window. Just have some fun and try them out!
SDK
If you don't want to use the console (perhaps you would like to use Athena as a query engine for an application you are developing) then you can make use of an SDK:
Examples:
Creating a client:
const client = new AthenaClient({ region: "REGION" });
Submitting a Query
const params = {
/** input parameters */
};
const command = new StartQueryExecutionCommand(params);
// async/await.
try {
const data = await client.send(command);
// process data.
} catch (error) {
// error handling.
} finally {
// finally.
}
Process the results
const params = {
/** input parameters */
};
const command = new GetQueryResultsCommand(input);
try {
const data = await client.send(command);
// process data.
} catch (error) {
// error handling.
} finally {
// finally.
}
The full example along with others can be seen here: Code samples
Note: There are other choices than the two noted here, such as using the CLI or a JDBC/ODBC, etc. See the following: Accessing Athena
Creating Data sources
In order for data that resides in S3 to be correctly consumed by Athena we first have to provide a data source which is fed from the S3 bucket or buckets we are interested in.
However, before we do that we need to understand what a data source is. A data source in Athena is a combination of both a dataset and a data catalogue, where the data catalogue describes the dataset.
Dataset
A dataset is a combination of:
- Table name
- Column names of the underlying table
- The data type of each column of the table
This information is all stored as meta data.
'tables and databases are containers for the metadata definitions that define a schema for underlying source data'
So essentially, the metadata is data that describes underlying data within the table. It is known as the Schema.
Data Catalogue
Within Athena, the organisation of all the metadata is known as the data catalogue.
Creating Tables
You can create tables manually using one of the following methods:
- Use the Athena console to run the Create Table Wizard.
- Use the Athena console to write Hive DDL statements in the Query Editor.
- Use the Athena API or CLI to run a SQL query string with DDL statements.
- Use the Athena JDBC or ODBC driver.
This will then cause Athena to use HiveQL DDL (Data Definition Language) behind the scenes when creating the the tables within AWS Glue.
Note: To learn more about Apache Hive see the following: Apache Hive
Crawlers
Instead of creating tables manually we can use crawlers.
'AWS Glue crawlers help discover the schema for datasets and register them as tables in the AWS Glue Data Catalog.'
Crawlers can be used to create schema for datasets and register them automatically as tables. However, a key advantage over manually defined tables is the ability for the crawler to keep the schema and the underlying data, say a bucket in S3, in sync.
Using a Crawler comes with it's Pro's and Con's. It can be very good for simple use cases where frequent changes to the data-set are occurring. However, in scenarios with more complex data-sets it may become more difficult to configure the Crawler to generate our expected resources. At this point, it may be more sensible to create tables manually in order to give more fine grained control over the Glue resources.
Saved Queries
Queries can be saved for easy re-use through both the console and programmatically. This, combined with parameterised queries, allows us to provide reusable SQL statements that we can call programmatically and without exposing the SQL underneath.

Parameterised Queries and Prepared Statements
We can use question mark place holders in our DML (Data Manipulation Language) queries in order create parameterised queries. We can choose to invoke these at point of declaration or we can create a prepared statement. Using the SDK, we provide the
execution-parameter argument to the request to start the query.
If we want to be able to create a statement we can invoke programmatically at a later time, we can save a prepared statement within the current workgroup. By taking advantage of prepared statements we are able to manage them separately to our application code. For example, if the underlying schema of the data source tables change we only need to update the prepared statement once, rather than updating multiple applications that reference it. There is also an extra layer of security against SQL injection provided by prepared statements. Athena interprets all arguments provided as literal values, as such, they are not treated as an executable command or as SQL operators. If we were to use a statement provided at the point of querying Athena we would be potentially exposing ourselves to a higher level of risk around SQL injection.
Example
PREPARE my_select2 FROM
SELECT * FROM "my_database"."my_table" WHERE year = ?
If we want to create this programmatically we can do so using the SDK.
For example:
const client = new AthenaClient(config);
const input = {
Description: 'Example Prepared Statement',
QueryStatement: 'SELECT * FROM "my_database"."my_table" WHERE year = ?',
StatementName: 'Example Statement',
WorkGroup: 'ExampleWorkgroup'
};
const command = new CreatePreparedStatementCommand(input);
const response = await client.send(command);
We can therefore take advantage of existing prepared statements within a workgroup to provide a more secure means to invoke known queries using parameters.
const client = new AthenaClient(config);
const input = {
StatementName: 'Example Statement',
WorkGroup: 'ExampleWorkgroup'
};
const command = new GetPreparedStatementCommand(input);
const response = await client.send(command);
Auditing
Out of the box, CloudTrail is able to track all of the calls made to Athena. We can track requests by user, role or service. When using parametrised queries, query strings are replaced with the statement 'HIDDEN_DUE_TO_SECURITY_REASONS'. This allows us to obscure potentially sensitive queries from capture in CloudTrail.
Considerations
Data formatting
Athena's SerDe (Serialiser/Deserialiser) expects each JSON document to be on separate line each, without any termination characters separating them.
See the following for other important considerations around the JSON formatting: JSON Best Practice
Final Thoughts
Athena is a useful tool to allow us to quickly interpret data we have stored in, for example, S3. There are some considerations to be made in regards to the formatting of the data to be considered, but once these are understood it is only a matter of configuring the resources in Glue to correctly represent the expected structure.
Athena offers many integrations with other AWS services such as CloudTrail, CloudFormation and S3 providing a convenient means to quickly ingest and analyse data.
The serverless nature of Athena also lends to it's convenience and cost effectiveness.
References:
Amazon Athena Athena - Getting Started Accessing Athena API Guide Best Practices JSON Best Practice JS SDK .Net Samples




